
К категории Большие данные (Big Data) относится информация, которую уже невозможно обрабатывать традиционными способами, в том числе структурированные данные, медиа и случайные объекты. Некоторые эксперты считают, что для работы с ними на смену традиционным монолитным системам пришли новые массивно-параллельные решения.
Что такое большие данные?
Из названия можно предположить, что термин «большие данные» относится просто к управлению и анализу больших объемов данных. Согласно отчету McKinsey Institute «Большие данные: новый рубеж для инноваций, конкуренции и производительности» ( Big data: The next frontier for innovation, competition and productivity), термин «большие данные» относится к наборам данных, размер которых превосходит возможности типичных баз данных (БД) по занесению, хранению, управлению и анализу информации. И мировые репозитарии данных, безусловно, продолжают расти. В представленном в середине 2011 г. отчете аналитической компании IDC «Исследование цифровой вселенной» (Digital Universe Study), подготовку которого спонсировала компания EMC, предсказывалось, что общий мировой объем созданных и реплицированных данных в 2011-м может составить около 1,8 зеттабайта (1,8 трлн. гигабайт) — примерно в 9 раз больше того, что было создано в 2006-м.
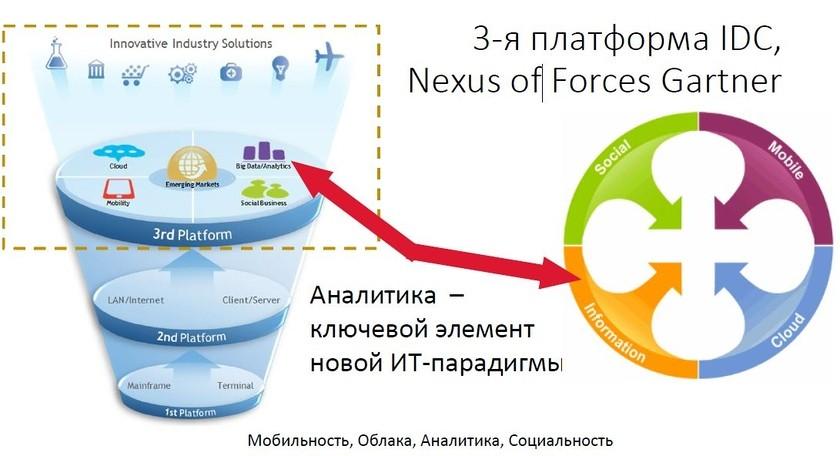
IDC, Nexus of Forces Gartner
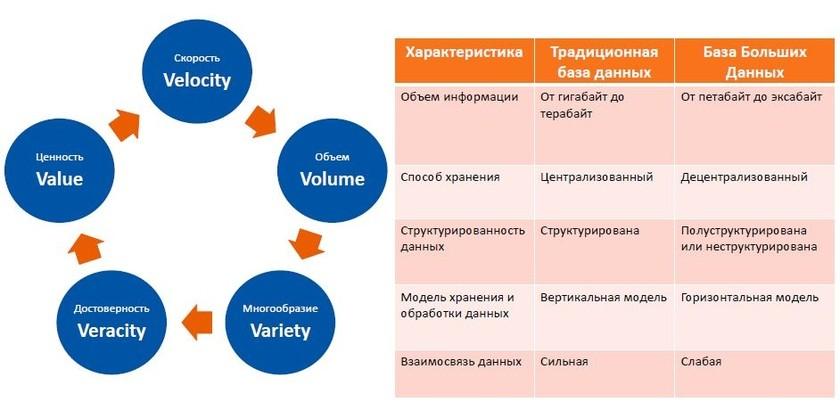
Традиционная база данных и База Больших Данных
Тем не менее «большие данные» предполагают нечто большее, чем просто анализ огромных объемов информации. Проблема не в том, что организации создают огромные объемы данных, а в том, что бóльшая их часть представлена в формате, плохо соответствующем традиционному структурированному формату БД, — это веб-журналы, видеозаписи, текстовые документы, машинный код или, например, геопространственные данные. Всё это хранится во множестве разнообразных хранилищ, иногда даже за пределами организации. В результате корпорации могут иметь доступ к огромному объему своих данных и не иметь необходимых инструментов, чтобы установить взаимосвязи между этими данными и сделать на их основе значимые выводы. Добавьте сюда то обстоятельство, что данные сейчас обновляются все чаще и чаще, и вы получите ситуацию, в которой традиционные методы анализа информации не могут угнаться за огромными объемами постоянно обновляемых данных, что в итоге и открывает дорогу технологиям больших данных.
В сущности понятие больших данных подразумевает работу с информацией огромного объема и разнообразного состава, весьма часто обновляемой и находящейся в разных источниках в целях увеличения эффективности работы, создания новых продуктов и повышения конкурентоспособности. Консалтинговая компания Forrester дает краткую формулировку: «Большие данные объединяют техники и технологии, которые извлекают смысл из данных на экстремальном пределе практичности».
Насколько велика разница между бизнес-аналитикой и большими данными?
Крейг Бати, исполнительный директор по маркетингу и директор по технологиям Fujitsu Australia, указывал, что бизнес-анализ является описательным процессом анализа результатов, достигнутых бизнесом в определенный период времени, между тем как скорость обработки больших данных позволяет сделать анализ предсказательным, способным предлагать бизнесу рекомендации на будущее. Технологии больших данных позволяют также анализировать больше типов данных в сравнении с инструментами бизнес-аналитики, что дает возможность фокусироваться не только на структурированных хранилищах.
Мэтт Слокум из O’Reilly Radar считает, что хотя большие данные и бизнес-аналитика имеют одинаковую цель (поиск ответов на вопрос), они отличаются друг от друга по трем аспектам.
- Большие данные предназначены для обработки более значительных объемов информации, чем бизнес-аналитика, и это, конечно, соответствует традиционному определению больших данных.
- Большие данные предназначены для обработки более быстро получаемых и меняющихся сведений, что означает глубокое исследование и интерактивность. В некоторых случаях результаты формируются быстрее, чем загружается веб-страница.
- Большие данные предназначены для обработки неструктурированных данных, способы использования которых мы только начинаем изучать после того, как смогли наладить их сбор и хранение, и нам требуются алгоритмы и возможность диалога для облегчения поиска тенденций, содержащихся внутри этих массивов.
Согласно опубликованной компанией Oracle белой книге «Информационная архитектура Oracle: руководство архитектора по большим данным» (Oracle Information Architecture: An Architect’s Guide to Big Data), при работе с большими данными мы подходим к информации иначе, чем при проведении бизнес-анализа.
Работа с большими данными не похожа на обычный процесс бизнес-аналитики, где простое сложение известных значений приносит результат: например, итог сложения данных об оплаченных счетах становится объемом продаж за год. При работе с большими данными результат получается в процессе их очистки путём последовательного моделирования: сначала выдвигается гипотеза, строится статистическая, визуальная или семантическая модель, на ее основании проверяется верность выдвинутой гипотезы и затем выдвигается следующая. Этот процесс требует от исследователя либо интерпретации визуальных значений или составления интерактивных запросов на основе знаний, либо разработки адаптивных алгоритмов «машинного обучения«, способных получить искомый результат. Причём время жизни такого алгоритма может быть довольно коротким.
Big Data≠Data Science
Big Data – это:
- ETL\ELT
- Технологии хранения больших объемов структурированных и не структурированных данных
- Технологии обработки таких данных
- Управление качеством данных
- Технологии предоставления данных потребителю
Data Science – это:
- Распознавание видео
- Распознавание текстов
- Распознавание речи
- Построение рекомендательных моделей
- Сегментация
- Кластеризация и т.д.
Методики анализа больших данных
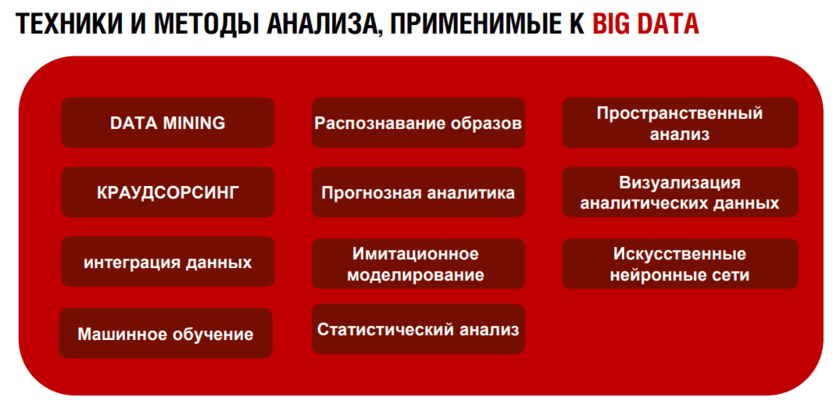
Существует множество разнообразных методик анализа массивов данных, в основе которых лежит инструментарий, заимствованный из статистики и информатики (например, машинное обучение). Список не претендует на полноту, однако в нем отражены наиболее востребованные в различных отраслях подходы. При этом следует понимать, что исследователи продолжают работать над созданием новых методик и совершенствованием существующих. Кроме того, некоторые из перечисленных них методик вовсе не обязательно применимы исключительно к большим данным и могут с успехом использоваться для меньших по объему массивов (например, A/B-тестирование, регрессионный анализ). Безусловно, чем более объемный и диверсифицируемый массив подвергается анализу, тем более точные и релевантные данные удается получить на выходе.
A/B testing. Методика, в которой контрольная выборка поочередно сравнивается с другими. Тем самым удается выявить оптимальную комбинацию показателей для достижения, например, наилучшей ответной реакции потребителей на маркетинговое предложение. Большие данные позволяют провести огромное количество итераций и таким образом получить статистически достоверный результат.
Association rule learning. Набор методик для выявления взаимосвязей, т.е. ассоциативных правил, между переменными величинами в больших массивах данных. Используется в data mining.
Classification. Набор методик, которые позволяет предсказать поведение потребителей в определенном сегменте рынка (принятие решений о покупке, отток, объем потребления и проч.). Используется в data mining.
Cluster analysis. Статистический метод классификации объектов по группам за счет выявления наперед не известных общих признаков. Используется в data mining.
Crowdsourcing. Методика сбора данных из большого количества источников.
Data fusion and data integration. Набор методик, который позволяет анализировать комментарии пользователей социальных сетей и сопоставлять с результатами продаж в режиме реального времени.
Data mining. Набор методик, который позволяет определить наиболее восприимчивые для продвигаемого продукта или услуги категории потребителей, выявить особенности наиболее успешных работников, предсказать поведенческую модель потребителей.
Ensemble learning. В этом методе задействуется множество предикативных моделей за счет чего повышается качество сделанных прогнозов.
Genetic algorithms. В этой методике возможные решения представляют в виде «хромосом», которые могут комбинироваться и мутировать. Как и в процессе естественной эволюции, выживает наиболее приспособленная особь.
Machine learning. Направление в информатике (исторически за ним закрепилось название «искусственный интеллект«), которое преследует цель создания алгоритмов самообучения на основе анализа эмпирических данных.
Natural language processing (NLP). Набор заимствованных из информатики и лингвистики методик распознавания естественного языка человека.
Network analysis. Набор методик анализа связей между узлами в сетях. Применительно к социальным сетям позволяет анализировать взаимосвязи между отдельными пользователями, компаниями, сообществами и т.п.
Optimization. Набор численных методов для редизайна сложных систем и процессов для улучшения одного или нескольких показателей. Помогает в принятии стратегических решений, например, состава выводимой на рынок продуктовой линейки, проведении инвестиционного анализа и проч.
Pattern recognition. Набор методик с элементами самообучения для предсказания поведенческой модели потребителей.
Predictive modeling. Набор методик, которые позволяют создать математическую модель наперед заданного вероятного сценария развития событий. Например, анализ базы данных CRM-системы на предмет возможных условий, которые подтолкнут абоненты сменить провайдера.
Regression. Набор статистических методов для выявления закономерности между изменением зависимой переменной и одной или несколькими независимыми. Часто применяется для прогнозирования и предсказаний. Используется в data mining.
Sentiment analysis. В основе методик оценки настроений потребителей лежат технологии распознавания естественного языка человека. Они позволяют вычленить из общего информационного потока сообщения, связанные с интересующим предметом (например, потребительским продуктом). Далее оценить полярность суждения (позитивное или негативное), степень эмоциональности и проч.
Signal processing. Заимствованный из радиотехники набор методик, который преследует цель распознавания сигнала на фоне шума и его дальнейшего анализа.
Spatial analysis. Набор отчасти заимствованных из статистики методик анализа пространственных данных – топологии местности, географических координат, геометрии объектов. Источником больших данных в этом случае часто выступают геоинформационные системы (ГИС).
Statistics. Наука о сборе, организации и интерпретации данных, включая разработку опросников и проведение экспериментов. Статистические методы часто применяются для оценочных суждений о взаимосвязях между теми или иными событиями.
Supervised learning. Набор основанных на технологиях машинного обучения методик, которые позволяют выявить функциональные взаимосвязи в анализируемых массивах данных.
Simulation. Моделирование поведения сложных систем часто используется для прогнозирования, предсказания и проработки различных сценариев при планировании.
Time series analysis. Набор заимствованных из статистики и цифровой обработки сигналов методов анализа повторяющихся с течением времени последовательностей данных. Одни из очевидных применений – отслеживание рынка ценных бумаг или заболеваемости пациентов.
Unsupervised learning. Набор основанных на технологиях машинного обучения методик, которые позволяют выявить скрытые функциональные взаимосвязи в анализируемых массивах данных. Имеет общие черты с Cluster Analysis.
Визуализация. Методы графического представления результатов анализа больших данных в виде диаграмм или анимированных изображений для упрощения интерпретации облегчения понимания полученных результатов.
Наглядное представление результатов анализа больших данных имеет принципиальное значение для их интерпретации. Не секрет, что восприятие человека ограничено, и ученые продолжают вести исследования в области совершенствования современных методов представления данных в виде изображений, диаграмм или анимаций.
Аналитический инструментарий
На 2011 год некоторые из перечисленных в предыдущем подразделе подходов или определенную их совокупность позволяют реализовать на практике аналитические движки для работы с большими данными. Из свободных или относительно недорогих открытых систем анализа Big Data можно порекомендовать:
- 1010data;
- Apache Chukwa;
- Apache Hadoop;
- Apache Hive;
- Apache Pig!;
- Jaspersoft;
- LexisNexis Risk Solutions HPCC Systems;
- MapReduce;
- Revolution Analytics (на базе языка R для матстатистики).
Особый интерес в этом списке представляет Apache Hadoop – ПО с открытым кодом, которое за последние пять лет испытано в качестве анализатора данных большинством трекеров акций[2]. Как только Yahoo открыла код Hadoop сообществу с открытым кодом, в ИТ-индустрии незамедлительно появилось целое направление по созданию продуктов на базе Hadoop. Практически все современные средства анализа больших данных предоставляют средства интеграции с Hadoop. Их разработчиками выступают как стартапы, так и общеизвестные мировые компании.
Рынки решений для управления большими данными
Платформы больших данных (BDP, Big Data Platform) как средство борьбы с цифровым хордингом
Возможность анализировать большие данные, в просторечии называемая Big Data, воспринимается как благо, причем однозначно. Но так ли это на самом деле? К чему может привести безудержное накопление данных? Скорее всего к тому, что отечественные психологи применительно к человеку называют патологическим накопительством, силлогоманией или образно «синдромом Плюшкина». По-английски порочная страсть собирать все подряд называют хордингом (от англ. hoard – «запас»). По классификации ментальных заболеваний хординг причислен к психическим расстройствам. В цифровую эпоху к традиционному вещественному хордингу добавляется цифровой (Digital Hoarding), им могут страдать как отдельные личности, так и целые предприятия и организации (подробнее).
Big data Landscape — Основные поставщики
Интерес к инструментам сбора, обработки, управления и анализа больших данных проявляли едва ли не все ведущие ИТ-компании, что вполне закономерно. Во-первых, они непосредственно сталкиваются с этим феноменом в собственном бизнесе, во-вторых, большие данные открывают отличные возможности для освоения новых ниш рынка и привлечения новых заказчиков.
|
|
|
На рынке появлялось множество стартапов, которые делают бизнес на обработке огромных массивов данных. Часть из них используют готовую облачную инфраструктуру, предоставляемую крупными игроками вроде Amazon.
|
|
|
История развития
Прогноз TmaxSoft: следующая «волна» Big Data потребует модернизации СУБД
Согласно отчету IDC, в связи ростом объемов данных, генерируемых подключенными к интернету устройствами, датчиками и другими технологиями, доходы, связанные с большими данными, увеличатся со $130 млрд в 2016 году до более чем $203 млрд к 2020 году.[3] Однако те компании, у которых нет ИТ-инфраструктуры, необходимой для адаптации к революции больших данных, не смогут получить выгоду от этого роста, считают эксперты компании TmaxSoft.
Предприятиям известно, что в накопленных ими огромных объемах данных содержится важная информация об их бизнесе и клиентах. Если компания сможет успешно применить эту информацию, то у нее будет значительное преимущество по сравнению с конкурентами, и она сможет предложить лучшие, чем у них, продукты и сервисы. Однако многие организации всё еще не могут эффективно использовать большие данные из-за того, что их унаследованная ИТ-инфраструктура неспособна обеспечить необходимую емкость систем хранения, процессы обмена данных, утилиты и приложения, необходимые для обработки и анализа больших массивов неструктурированных данных для извлечения из них ценной информации, указали в TmaxSoft.
Кроме того, увеличение процессорной мощности, необходимой для анализа постоянно увеличивающихся объемов данных, может потребовать значительных инвестиций в устаревшую ИТ-инфраструктуру организации, а также дополнительных ресурсов для сопровождения, которые можно было бы использовать для разработки новых приложений и сервисов.
По мнению Андрея Ревы, исполнительного директора TmaxSoft Россия, эти факторы приведут к тому, что организации, которые продолжают использовать унаследованную инфраструктуру, в будущем будут вынуждены заплатить намного больше за переход на актуальные технологии либо не смогут получить никакого эффекта от революции больших данных.
Феномен больших данных заставил многие предприятия осознать необходимость сбора, анализа и хранения структурированных и неструктурированных данных. Однако для внедрения этих процессов нужен план действий и правильные инструменты оптимизации процессов. А реально получать ощутимый эффект от больших данных многие компании не в состоянии из-за использования унаследованных СУБД, в которых не хватает функциональности и масштабируемости, и в результате революция больших данных никак не помогает их бизнесу, — пояснил свой прогноз Андрей Рева.
По убеждению представителя TmaxSoft, предприятиям нужна стратегия, учитывающая, среди прочего, источники данных для извлечения, жизненный цикл данных, совместимость разных реляционных СУБД и масштабируемость хранения.
Прогноз EMC: BigData и аналитика в реальном времени объединятся
В 2016 году мы познакомимся с новой главой истории развития аналитики «больших данных» по мере развития двухуровневой модели обработки. Первый уровень будет представлять собой «традиционную» аналитику BigData, когда большие массивы данных подвергаются анализу не в режиме реального времени. Новый, второй уровень обеспечит возможность анализа относительно больших объемов данных в реальном времени, в основном за счет технологий аналитики в памяти (in-memory). В этой новой фазе развития BigData, такие технологии как DSSD, Apache Spark и GemFire будут столь же важны, как Hadoop. Второй уровень предложит нам одновременно новые и привычные способы использования «озер данных» — для «аналитики на лету» с целью влияния на события, в то время, когда они происходят. Это открывает новые возможности для бизнеса в таких масштабах, которых раньше никто не видел.
Но для того, чтобы аналитика в памяти стала реальностью, необходимо, чтобы произошло два события. Во-первых, поддерживающие технологии должны получить необходимое развитие, чтобы обеспечить достаточные объемы памяти для размещения действительно масштабных наборов данных. Также нужно подумать о том, как эффективно перемещать данные между большими объектными хранилищами и системами, ведущими анализ в памяти. Ведь эти два элемента работают в принципиально разных режимах, и ИТ-группам нужно будет создать особые условия, чтобы данные могли перемещаться туда и обратно с нужной скоростью и прозрачно для пользователей. Работы уже ведутся, появляются новые объектные хранилища, специальные флеш-массивы для монтажа в стойку, а также специальные технологии, которые могут объединить их в одну систему. Инициативы с открытым кодом будут играть важную роль в поиске ответа на этот вызов.
Во-вторых, масштабные среды вычислений в памяти требуют устойчивости и динамичности данных. Проблема состоит в том, что обеспечивая персистентность данных в памяти, мы делаем устойчивыми также любые их дефекты. В результате в 2016 году мы увидим появления систем хранения для сред, проводящих обработку данных в памяти. Они будут предоставлять сервисы дедупликации, снимков состояния, многоуровневого хранения, кеширования, репликации, а также возможность определения последнего состояния, когда данные были верными и система работала корректно. Эти функции будут крайне важны по мере перехода к аналитике в реальном времени, когда более безопасные технологии обработки данных в памяти станут коммерческими в 2016 году.
Gartner исключила «Большие данные» из популярных трендов
6 октября 2015 года стало известно об исключении из отчета Gartner «Цикл зрелости технологий 2015» сведений о больших данных. Исследователи объяснили это размыванием термина — входящие в понятие «большие данные» технологии стали повседневной реальностью бизнеса[4].
Отчет Gartner «Цикл зрелости технологий» (Hype Cycle for Emerging Technologies) взбудоражил отрасль отсутствием технологии сбора и обработки больших массивов данных. Свое решение аналитики компании объяснили тем, что в состав понятия «большие данные» входит большое количество технологий, активно применяющихся на предприятиях, они частично относятся к другим популярным сферам и тенденциям и стали повседневным рабочим инструментом.
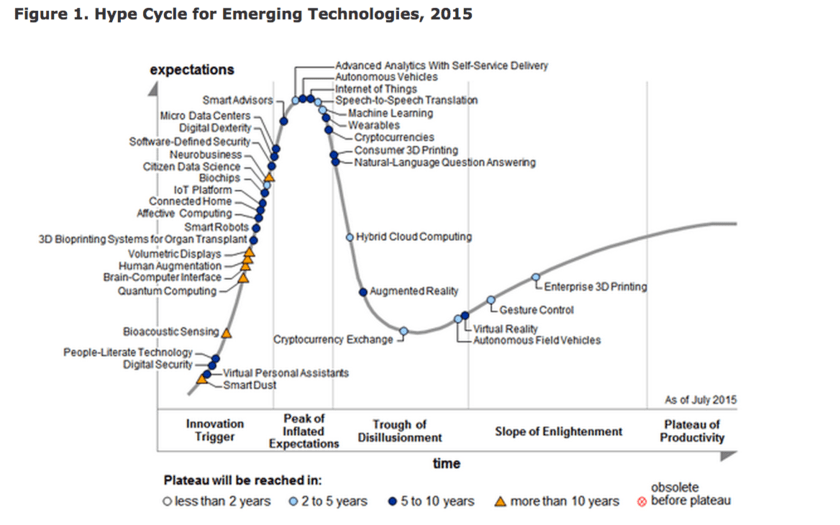
Диаграмма Gartner «Hype Cycle for Emerging Technologies 2015»
«Изначально понятие «большие данные» расшифровывали через определение из трех «V»: volume, velocity, variety. Под этим термином подразумевалась группа технологий хранения, обработки и анализа данных большого объема, с изменчивой структурой и высокой скоростью обновления. Но реальность показала, что получение выгоды в бизнес-проектах осуществляется по тем же принципам, что и раньше. А описываемые технологические решения сами по себе не создали никакой новой ценности, лишь ускорив обработку большого количества данных. Ожидания были очень высокие, и список технологий больших данных интенсивно рос. Очевидно, что вследствие этого границы понятия размылись до предела», — поведал Святослав Штумпф, главный эксперт группы маркетинга продуктов «Петер-Сервис».
Дмитрий Шепелявый, заместитель генерального директора SAP CIS (САП СНГ), считает — тема больших данных не исчезла, а трансформировалась во множество различных сценариев:
«Примерами здесь могут быть ремонты по состоянию, точное земледелие (precision farming), системы по противодействию мошенничеству, системы в медицине, позволяющие на качественно новом уровне диагностировать и лечить пациентов. А также планирование логистической системы и транспортировки в режиме реального времени, усовершенствованная бизнес-аналитика для поддержки и сопровождения основных функций компаний. Один из основных трендов сейчас — Интернет вещей, позволяющий связывать машины между собой (machine-to-machine). Устанавливаемые электронные датчики производят миллионы транзакций в секунду, и необходимо надежное решение, способное трансформировать, сохранить и работать с ними в режиме реального времени».
В мае 2015 года Эндрю Уайт (Andrew White), вице-президент по исследованиям Gartner, в своем блоге размышлял:
«[Интернет вещей Internet of Things (IoT)|Интернет вещей (Internet of Things, IoT)] затмит собой большие данные, как слишком сфокусированную технологию. Она может породить еще несколько эффективных решений и инструментов, но платформой будущего, которая в долгосрочной перспективе повысит нашу продуктивность, станет именно интернет вещей».
Аналогичные идеи раньше — по результатам отчета Gartner за 2014 год, опубликовал обозреватель Forbes Гил Пресс (Gil Press).
По мнению Дмитрия Шепелявого, наступила эпоха, когда важно не просто уметь аккумулировать информацию, а извлекать из нее бизнес-выгоду. Первыми к этому выводу пришли индустрии, которые непосредственно работают с потребителем: телекоммуникационная и банковская, ритейл. Теперь процессы взаимодействия выходят на новый уровень, позволяя наладить связь между различными устройствами с использованием инструментов дополненной реальности и открывают новые возможности оптимизации бизнес-процессов компаний.
«Понятие «большие данные» потеряло интерес для реального бизнеса, на диаграмме Gartner его место заняли другие технологии с более четким и понятным бизнесу звучанием», — подчеркнул Святослав Штумпф.
Это, в первую очередь, машинное обучение — средства поиска правил и связей в очень больших объемах информации. Такие технологии позволяют не просто проверять гипотезы, но искать неизвестные ранее факторы влияния. Сегмент решений по хранению данных и параллельному доступу к ним (NoSQL Database), по предварительной обработке потоков информации (Marshalling), решения для визуализации и самостоятельного анализа (Advanced Analytics with Self-Service Delivery). Кроме того, по мнению эксперта, сохраняют свое значение средства интеллектуального анализа данных (Business Intelligence и Data Mining), выходящие на новый технологический уровень.
В понимании «Яндекса», согласно заявлению пресс-службы компании, большие данные никуда не исчезли и не трансформировались. Для обработки больших массивов данных компания использует те же технологии и алгоритмы, что применяет в интернет-поиске, сервисе «Яндекс.Пробки», в машинном переводчике, в рекомендательной платформе, в рекламе. Алгоритмы основаны на умении компании: накапливать, хранить и обрабатывать большие объемы данных и делать их полезными бизнесу. Области применения Yandex Data Factory не ограничены — главное, чтобы были данные для анализа. В фокусе компании на 6 октября 2015 года:
- ритейл,
- финансы,
- логистика,
- телеком,
- энергетика,
- ЖКХ,
- нефтегаз,
- аэрокосмическая отрасль.
Big data и ценовая дискриминация клиентов
Ниже приведены избранные фрагменты из статьи Морган Кеннеди (Morgan Kennedy) опубликованной 6 февраля 2015 на сайте InsidePrivacy, посвященном проблеме защиты неприкосновенности частной жизни[5].
5 февраля 2015 года Белый дом опубликовал доклад, в котором обсуждался вопрос о том, как компании используют «большие данные» для установления различных цен для разных покупателей — практика, известная как «ценовая дискриминация» или «дифференцированное ценообразование» (personalized pricing). Отчет описывает пользу «больших данных» как для продавцов, так и покупателей, и его авторы приходят к выводу о том, что многие проблемные вопросы, возникшие в связи с появлением больших данных и дифференцированного ценообразования, могут быть решены в рамках существующего антидискриминационного законодательства и законов, защищающих права потребителей.
В докладе отмечается, что в это время имеются лишь отдельные факты, свидетельствующие о том, как компании используют большие данные в контексте индивидуализированного маркетинга и дифференцированного ценообразования. Этот сведения показывают, что продавцы используют методы ценообразования, которые можно разделить на три категории:
- изучение кривой спроса;
- Наведение (steering) и дифференцированное ценообразование на основе демографических данных; и
- целевой поведенческий маркетинг (поведенческий таргетинг — behavioral targeting) и индивидуализированное ценообразование.
Изучение кривой спроса: С целью выяснения спроса и изучения поведения потребителей маркетологи часто проводят эксперименты в этой области, в ходе которых клиентам случайным образом назначается одна из двух возможных ценовых категорий. «Технически эти эксперименты являются формой дифференцированного ценообразования, поскольку их следствием становятся разные цены для клиентов, даже если они являются «недискриминационными» в том смысле, что у всех клиенты вероятность «попасть» на более высокую цену одинакова».
Наведение (steering): Это практика представления продуктов потребителям на основе их принадлежности к определенной демографической группе. Так, веб-сайт компьютерной компании может предлагать один и тот же ноутбук различным типам покупателей по разным ценам, уставленным на основе сообщённой ими о себе информации (например, в зависимости от того, является ли данный пользователь представителем государственных органов, научных или коммерческих учреждений, или же частным лицом) или от их географического расположения (например, определенного по IP-адресу компьютера).
Целевой поведенческий маркетинг и индивидуализированное ценообразование: В этих случаях персональные данные покупателей используются для целевой рекламы и индивидуализированного назначения цен на определенные продукты. Например, онлайн-рекламодатели используют собранные рекламными сетями и через куки третьих сторон данные об активности пользователей в интернете для того, чтобы нацелено рассылать свои рекламные материалы. Такой подход, с одной стороны, дает возможность потребителям получить рекламу представляющих для них интерес товаров и услуг, Он, однако, может вызвать озабоченность тех потребителей, которые не хотят, чтобы определенные виды их персональных данных (такие, как сведения о посещении сайтов, связанных с медицинскими и финансовыми вопросами) собирались без их согласия.
Хотя целевой поведенческий маркетинг широко распространен, имеется относительно мало свидетельств индивидуализированного ценообразования в онлайн-среде. В отчете высказывается предположение, что это может быть связано с тем, что соответствующие методы все ещё разрабатываются, или же с тем, что компании не спешат использовать индивидуальное ценообразование (либо предпочитают о нём помалкивать) — возможно, опасаясь негативной реакции со стороны потребителей.
Авторы отчета полагают, что «для индивидуального потребителя использование больших данных, несомненно, связано как с потенциальной отдачей, так и с рисками». Признавая, что при использовании больших данных появляются проблемы прозрачности и дискриминации, отчет в то же время утверждает, что существующих антидискриминационных законов и законов по защиты прав потребителей достаточно для их решения. Однако в отчете также подчеркивается необходимость «постоянного контроля» в тех случаях, когда компании используют конфиденциальную информацию непрозрачным образом либо способами, которые не охватываются существующей нормативно-правовой базой.
Данный доклад является продолжением усилий Белого дома по изучению применения «больших данных» и дискриминационного ценообразования в Интернете, и соответствующих последствий для американских потребителей. Ранее уже сообщалось[6] о том, что рабочая группа Белого дома по большим данным опубликовала в мае 2014 года свой доклад по этому вопросу. Федеральная комиссия по торговле (FTC) также рассматривала эти вопросы в ходе проведенного ею в сентября 2014 года семинара по дискриминации в связи с использованием больших данных[7].
Gartner развеивает мифы о «Больших данных»
В аналитической записке осени 2014 года Gartner перечислен ряд распространенных среди ИТ-руководителей мифов относительно Больших Данных и приводятся их опровержения.
- Все внедряют системы обработки Больших Данных быстрее нас
Интерес к технологиям Больших Данных рекордно высок: в 73% организаций, опрошенных аналитиками Gartner в этом году, уже инвестируют в соответствующие проекты или собираются. Но большинство таких инициатив пока еще на самых ранних стадиях, и только 13% опрошенных уже внедрили подобные решения. Сложнее всего — определить, как извлекать доход из Больших Данных, решить, с чего начать. Во многих организациях застревают на пилотной стадии, поскольку не могут привязать новую технологию к конкретным бизнес-процессам.
- У нас так много данных, что нет нужды беспокоиться о мелких ошибках в них
Некоторые ИТ-руководители считают, что мелкие огрехи в данных не влияют на общие результаты анализа огромных объемов. Когда данных много, каждая ошибка в отдельности действительно меньше влияет на результат, отмечают аналитики, но и самих ошибок становится больше. Кроме того, большая часть анализируемых данных — внешние, неизвестной структуры или происхождения, поэтому вероятность ошибок растет. Таким образом, в мире Больших Данных качество на самом деле гораздо важнее.
- Технологии Больших Данных отменят нужду в интеграции данных
Большие Данные обещают возможность обработки данных в оригинальном формате с автоматическим формированием схемы по мере считывания. Считается, что это позволит анализировать информацию из одних и тех же источников с помощью нескольких моделей данных. Многие полагают, что это также даст возможность конечным пользователям самим интерпретировать любой набор данных по своему усмотрению. В реальности большинству пользователей часто нужен традиционный способ с готовой схемой, когда данные форматируются соответствующим образом, и имеются соглашения об уровне целостности информации и о том, как она должна соотноситься со сценарием использования.
- Хранилища данных нет смысла использовать для сложной аналитики
Многие администраторы систем управления информацией считают, что нет смысла тратить время на создание хранилища данных, принимая во внимание, что сложные аналитические системы пользуются новыми типами данных. На самом деле во многих системах сложной аналитики используется информация из хранилища данных. В других случаях новые типы данных нужно дополнительно готовить к анализу в системах обработки Больших Данных; приходится принимать решения о пригодности данных, принципах агрегации и необходимом уровне качества — такая подготовка может происходить вне хранилища.
- На смену хранилищам данных придут озера данных
В реальности поставщики вводят заказчиков в заблуждение, позиционируя озера данных (data lake) как замену хранилищам или как критически важные элементы аналитической инфраструктуры. Основополагающим технологиям озер данных не хватает зрелости и широты функциональности, присущей хранилищам. Поэтому руководителям, отвечающим за управление данными, стоит подождать, пока озера достигнут того же уровня развития, считают в Gartner.
Accenture: 92% внедривших системы больших данных, довольны результатом
Согласно исследованию Accenture (Аксенчер) (осень 2014 года), 60% компаний уже успешно завершили как минимум один проект, связанный с большими данными. Подавляющее большинство (92%) представителей этих компаний оказалось довольно результатом, а 89% заявили, что большие данные стали крайне важной частью преобразования их бизнеса. Среди остальных опрошенных 36% не задумывались о внедрении данной технологии, а 4% пока не закончили свои проекты.
В исследовании Accenture приняло участие более 1000 руководителей компаний из 19 стран мира. В основу исследования легли данные опроса Economist Intelligence Unit среди 1135 респондентов по всему миру[8].
Среди главных преимуществ больших данных опрошенные назвали:
- «поиск новых источников дохода» (56%),
- «улучшение опыта клиентов» (51%),
- «новые продукты и услуги» (50%) и
- «приток новых клиентов и сохранение лояльности старых» (47%).
При внедрении новых технологий многие компании столкнулись с традиционными проблемами. Для 51% камнем преткновения стала безопасность, для 47% — бюджет, для 41% — нехватка необходимых кадров, а для 35% — сложности при интеграции с существующей системой. Практически все опрошенные компании (около 91%) планируют в скором времени решать проблему с нехваткой кадров и нанимать специалистов по большим данным.
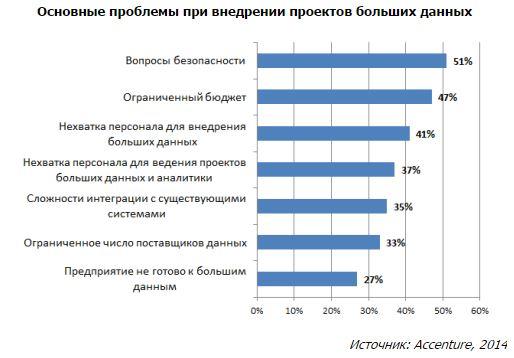
Компании оптимистично оценивают будущее технологий больших данных. 89% считают, что они изменят бизнес столь же сильно, как и интернет. 79% респондентов отметили, что компании, которые не занимаются большими данными, потеряют конкурентное преимущество.
Впрочем, опрошенные разошлись во мнении о том, что именно стоит считать большими данными. 65% респондентов считают, что это «большие картотеки данных», 60% уверены, что это «продвинутая аналитика и анализ», а 50% — что это «данные инструментов визуализации».
Мадрид тратит 14,7 млн евро на управление большими данными
В июле 2014 г. стало известно о том, что Мадрид будет использовать технологии big data для управления городской инфраструктурой. Стоимость проекта — 14,7 млн евро, основу внедряемых решений составят технологии для анализа и управления большими данными. С их помощью городская администрация будет управлять работой с каждым сервис-провайдером и соответствующим образом оплачивать ее в зависимости от уровня услуг.
Речь идет о подрядчиках администрации, которые следят за состоянием улиц, освещением, ирригацией, зелеными насаждениями, осуществляют уборку территории и вывоз, а также переработку мусора. В ходе проекта для специально выделенных инспекторов разработаны 300 ключевых показателей эффективности работы городских сервисов, на базе которых ежедневно будет осуществляться 1,5 тыс. различных проверок и замеров. Кроме того, город начнет использование инновационной технологической платформы под названием Madrid iNTeligente (MiNT) — Smarter Madrid.
Эксперты: Пик моды на Big Data
Все без исключения вендоры на рынке управления данными в это время ведут разработку технологий для менеджмента Big Data. Этот новый технологический тренд также активно обсуждается профессиональными сообществом, как разработчиками, так и отраслевыми аналитиками и потенциальными потребителями таких решений.
Как выяснила компания Datashift, по состоянию на январь 2013 года волна обсуждений вокруг «больших данных» превысила все мыслимые размеры. Проанализировав число упоминаний Big Data в социальных сетях, в Datashift подсчитали, что за 2012 год этот термин употреблялся около 2 млрд раз в постах, созданных около 1 млн различных авторов по всему миру. Это эквивалентно 260 постам в час, причем пик упоминаний составил 3070 упоминаний в час.
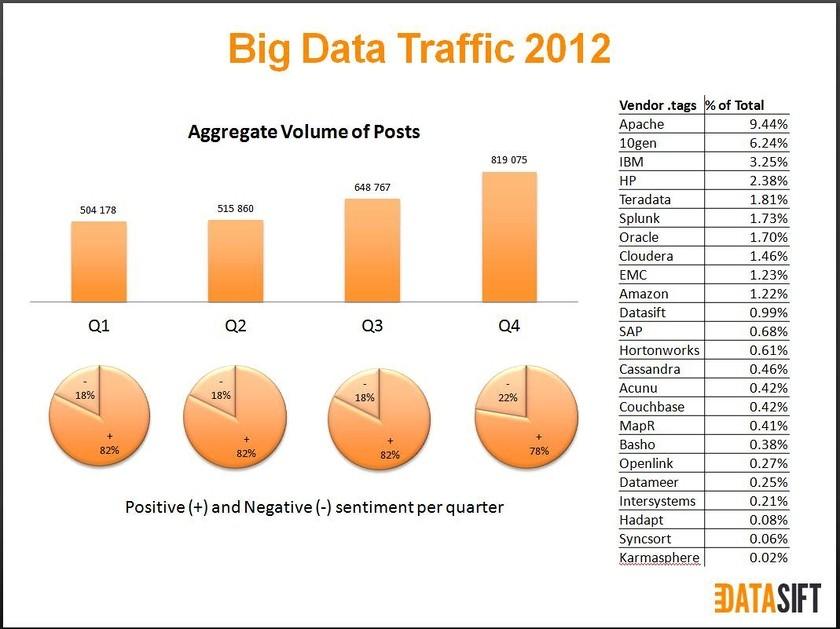
Обсуждения Big Data в сети идут весьма активно. Причем, как видно из представленных выше круговых диаграмм, пик обсуждений только нарастает: если в первом квартале 2012 года насчитывалось более 504 тыс. упоминаний термина, то в четвертом квартале – уже более 800 тыс. Главные темы обсуждений применительно к большим данным – мифы и реальность, опыт использования, человеческий фактор, возврат инвестиций, новые технологии. Среди вендоров чаще всего упоминались компании Apache, 10gen, IBM, HP и Teradata.
Gartner: Каждый второй ИТ-директор готов потратиться на Big data
После нескольких лет экспериментов с технологиями Big data и первых внедрений в 2013 году адаптация подобных решений значительно возрастет, прогнозируют в Gartner[9]. Исследователи опросили ИТ-лидеров во всем мире и установили, что 42% опрошенных уже инвестировали в технологии Big data или планируют совершить такие инвестиции в течение ближайшего года (данные на март 2013 года).
Компании вынуждены потратиться на технологии обработки больших данных, поскольку информационный ландшафт стремительно меняется, требую новых подходов к обработки информации. Многие компании уже осознали, что большие массивы данных являются критически важными, причем работа с ними позволяет достичь выгод, не доступных при использовании традиционных источников информации и способов ее обработки. Кроме того, постоянное муссирование темы «больших данных» в СМИ подогревает интерес к соответствующим технологиям.
Фрэнк Байтендидк (Frank Buytendijk), вице-президент Gartner, даже призвал компании умерить пыл, поскольку некоторые проявляют беспокойство, что отстают от конкурентов в освоении Big data.
«Волноваться не стоит, возможности для реализации идей на базе технологий «больших данных» фактически безграничны», — заявил он.
По прогнозам Gartner, к 2015 году 20% компаний списка Global 1000 возьмут стратегический фокус на «информационную инфраструктуру».
В ожидании новых возможностей, которые принесут с собой технологии обработки «больших данных», уже сейчас многие организации организуют процесс сбора и хранения различного рода информации.
Для образовательных и правительственных организаций, а также компаний отрасли промышленности наибольший потенциал для трансформации бизнеса заложен в сочетании накопленных данных с так называемыми dark data (дословно – «темными данными»), к последним относятся сообщения электронной почты, мультимедиа и другой подобный контент. По мнению Gartner, в гонке данных победят именно те, кто научится обращаться с самыми разными источниками информации.
Опрос Cisco: Big Data поможет увеличить ИТ-бюджеты
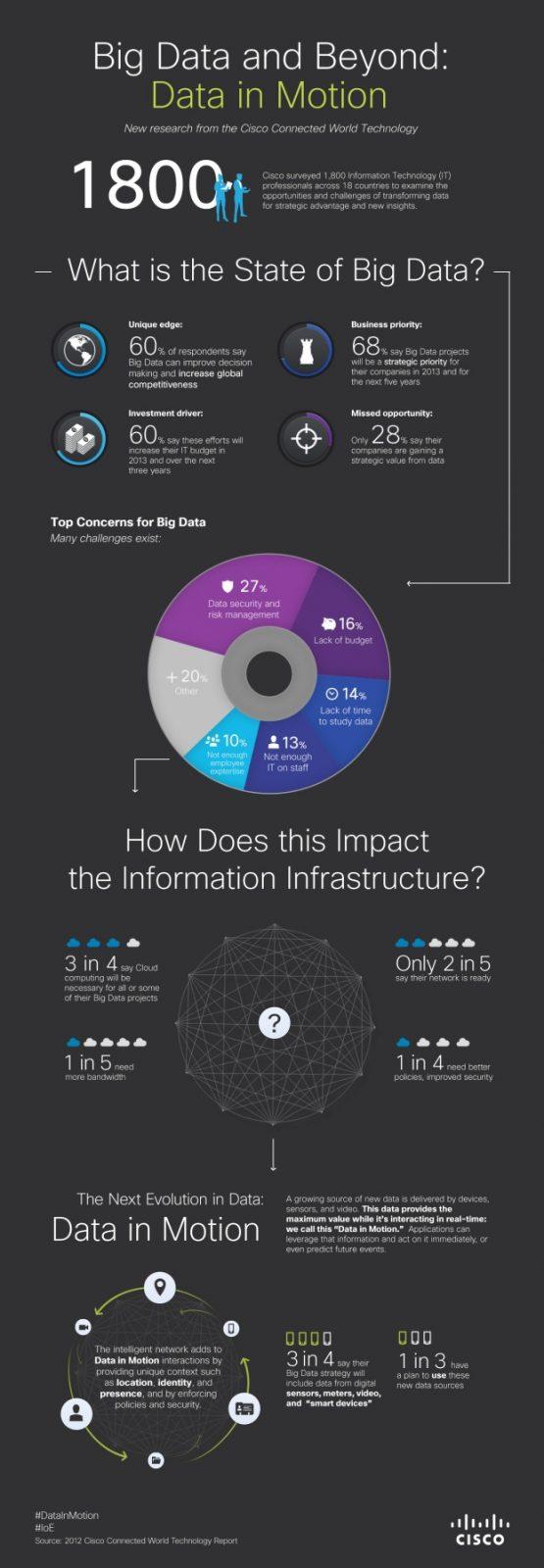
В ходе исследования (весна 2013 года) под названием Cisco Connected World Technology Report, проведенного в 18 странах независимой аналитической компанией InsightExpress, были опрошены 1 800 студентов колледжей и такое же количество молодых специалистов в возрасте от 18 до 30 лет. Опрос проводился, чтобы выяснить уровень готовности ИТ-отделов к реализации проектов Big Data и получить представление о связанных с этим проблемах, технологических изъянах и стратегической ценности таких проектов.
Большинство компаний собирает, записывает и анализирует данные. Тем не менее, говорится в отчете, многие компании в связи с Big Data сталкиваются с целым рядом сложных деловых и информационно-технологических проблем. К примеру, 60 процентов опрошенных признают, что решения Big Data могут усовершенствовать процессы принятия решений и повысить конкурентоспособность, но лишь 28 процентов заявили о том, что уже получают реальные стратегические преимущества от накопленной информации.
Более половины опрошенных ИТ-руководителей считают, что проекты Big Data помогут увеличить ИТ-бюджеты в их организациях, так как будут предъявляться повышенные требования к технологиям, персоналу и профессиональным навыкам. При этом более половины респондентов ожидают, что такие проекты увеличат ИТ-бюджеты в их компаниях уже в 2012 году. 57 процентов уверены в том, что Big Data увеличит их бюджеты в течение следующих трех лет.
81 процент респондентов заявили, что все (или, по крайней мере, некоторые) проекты Big Data потребуют применения облачных вычислений. Таким образом, распространение облачных технологий может сказаться на скорости распространения решений Big Data и на ценности этих решений для бизнеса.
Компании собирают и используют данные самых разных типов, как структурированные, так и неструктурированные. Вот из каких источников получают данные участники опроса (Cisco Connected World Technology Report):
- 74 процента собирают текущие данные;
- 55 процентов собирают исторические данные;
- 48 процентов снимают данные с мониторов и датчиков;
- 40 процентов пользуются данными в реальном времени, а затем стирают их. Чаще всего данные в реальном времени используются в Индии (62 процента), США (60 процентов) и Аргентине (58 процентов);
- 32 процента опрошенных собирают неструктурированные данные – например, видео. В этой области лидирует Китай: там неструктурированные данные собирают 56 процентов опрошенных.
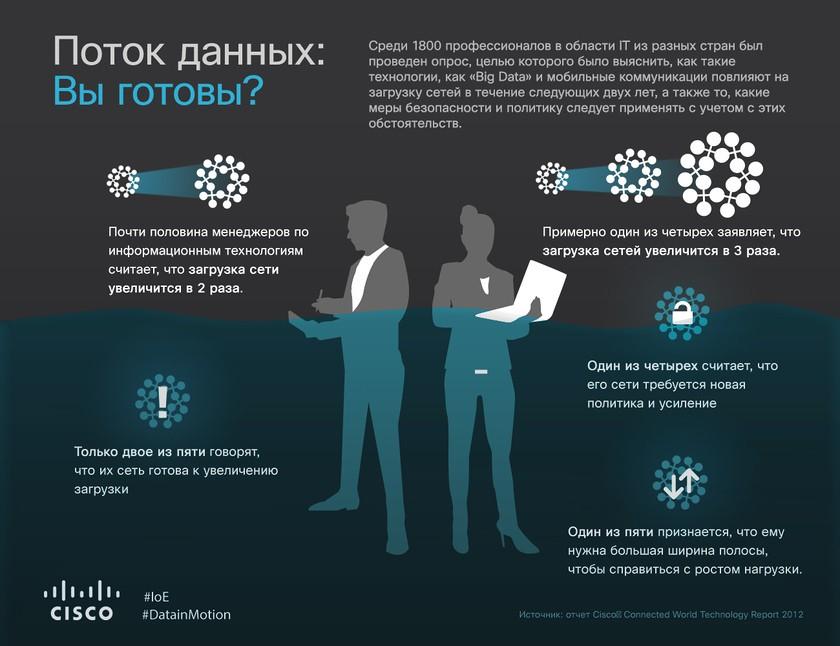
Почти половина (48 процентов) ИТ-руководителей прогнозирует удвоение нагрузки на их сети в течение ближайших двух лет. (Это особенно характерно для Китая, где такой точки зрения придерживаются 68 процентов опрошенных, и Германии – 60 процентов). 23 процента респондентов ожидают утроения сетевой нагрузки на протяжении следующих двух лет. При этом лишь 40 процентов респондентов заявили о своей готовности к взрывообразному росту объемов сетевого трафика.
27 процентов опрошенных признали, что им необходимы более качественные ИТ-политики и меры информационной безопасности.
21 процент нуждается в расширении полосы пропускания.
Big Data открывает перед ИТ-отделами новые возможности для наращивания ценности и формирования тесных отношений с бизнес-подразделениями, позволяя повысить доходы и укрепить финансовое положение компании. Проекты Big Data делают ИТ-подразделения стратегическим партнером бизнес-подразделений.
По мнению 73 процентов респондентов, именно ИТ-отдел станет основным локомотивом реализации стратегии Big Data. При этом, считают опрошенные, другие отделы тоже будут подключаться к реализации этой стратегии. Прежде всего, это касается отделов финансов (его назвали 24 процента респондентов), научно-исследовательского (20 процентов), операционного (20 процентов), инженерного (19 процентов), а также отделов маркетинга (15 процентов) и продаж (14 процентов).
Gartner: Для управления большими данными нужны миллионы новых рабочих мест
Мировые ИТ расходы достигнут $3,7 млрд к 2013 году, что на 3,8% больше расходов на информационные технологии в 2012 году (прогноз на конец года составляет $3,6 млрд). Сегмент больших данных (big data) будет развиваться гораздо более высокими темпами, говорится в отчете Gartner[10].
К 2015 году 4,4 млн рабочих мест в сфере информационных технологий будет создано для обслуживания больших данных, из них 1,9 млн рабочих мест – в США. Более того, каждое такое рабочее место повлечет за собой создание трех дополнительных рабочих мест за пределами сферы ИТ, так что только в США в ближайшие четыре года 6 млн человек будет трудиться для поддержания информационной экономики.
По мнению экспертов Gartner, главная проблема состоит в том, что в отрасли для этого недостаточно талантов: как частная, так и государственная образовательная система, например, в США не способны снабжать отрасль достаточным количеством квалифицированных кадров. Так что из упомянутых новых рабочих мест в ИТ кадрами будет обеспечено только одно из трех.
Аналитики полагают, что роль взращивания квалифицированных ИТ кадров должны брать на себя непосредственно компании, которые в них остро нуждаются, так как такие сотрудники станут пропуском для них в новую информационную экономику будущего.
Первый скепсис в отношении «Больших данных»
Аналитики компаний Ovum и Gartner предполагают, что для модной в 2012 году темы больших данных может настать время освобождения от иллюзий.
Термином «Большие Данные», в это время как правило, обозначают постоянно растущий объем информации, поступающей в оперативном режиме из социальных медиа, от сетей датчиков и других источников, а также растущий диапазон инструментов, используемых для обработки данных и выявления на их основе важных бизнес-тенденций.
«Из-за шумихи (или несмотря на нее) относительно идеи больших данных производители в 2012 году с огромной надеждой смотрели на эту тенденцию», — отметил Тони Байер, аналитик Ovum.
Байер сообщил, что компания DataSift провела ретроспективный анализ упоминаний больших данных в Twitter за 2012 год. Ограничивая поиск производителями, аналитики хотели сфокусироваться на восприятии этой идеи рынком, а не широким сообществом пользователей. Аналитики выявили 2,2 млн твитов от более чем 981 тыс. авторов.
Эти данные различались в разных странах. Хотя общепринято убеждение, что США лидирует по показателю установленных платформ для работы с большими данными, пользователи из Японии, Германии и Франции часто были более активны в обсуждениях.
Идея Больших Данных привлекла столь большое внимание, что об этом широко писала даже бизнес-пресса, а не только специализированные издания.
Число положительных отзывов о больших данных со стороны производителей в три раза превышало число отрицательных, хотя в ноябре в связи с покупкой компанией HP компании Autonomy наблюдался всплеск негатива.
Концепцию больших данных ожидают намного более суровые времена, хотя, миновав их, эта идеология достигнет зрелости.
«Для сторонников больших данных наступает время расставания с иллюзиями», — пояснила Светлана Сикулар, аналитик Gartner. Она сослалась на обязательную стадию, входящую в классическую кривую цикла популярности (Hype Cycle), которую используют в Gartner.
Даже среди тех клиентов, которые добились наибольших успехов с использованием Hadoop, многие «утрачивают иллюзии».
«Они отнюдь не чувствуют, что находятся впереди других, и полагают, что успех выпадает другим, в то время как они переживают не лучшие времена. У этих организаций потрясающие идеи, а теперь они разочарованы из-за трудностей в выработке надежных решений», — сказала Сикулар.
Впрочем, источником оптимизма для сторонников больших данных в это время может быть то, что следующий цикл на кривой популярности, а также завершающие этапы имеют весьма многообещающие названия, а именно «склон просвещения» и «плато продуктивности».
Медленные СХД сдерживают развитие «Больших данных»
Если производительность современных вычислительных систем за несколько десятилетий выросла на многие порядки и не идет ни в какое сравнение с первыми персональными ПК образца начала 1980-х гг. прошлого столетия, то с СХД дела обстоят гораздо хуже. Безусловно, доступные объемы многократно увеличились (впрочем, они по-прежнему в дефиците), резко снизилась стоимость хранения информации в пересчете на бит (хотя готовые системы по-прежнему слишком дорогие), однако скорость извлечения и поиска нужной информации оставляет желать лучшего.
Если не брать в рассмотрение пока еще слишком дорогие и не вполне надежные и долговечные флэш-накопители, технологии хранения информации не очень далеко ушли вперед. По-прежнему приходится иметь дело с жесткими дисками, скорость вращения пластин которых даже в самых дорогих моделях ограничена на уровне 15 тыс. об./мин. Коль скоро речь идет о больших данных, очевидно, немалое их количество (если не подавляющее) размещается на накопителях со скоростью вращения шпинделя 7,2 тыс. об./мин. Достаточно прозаично и грустно.
Обозначенная проблема лежит на поверхности и хорошо знакома ИТ-директорам компаний. Впрочем, она далеко не единственная[11]:
- Технологическое отставание.
Большие данные могут превратиться в большую головную боль или открыть большие возможности перед правительственными учреждениями, если только они сумеют ими воспользоваться. К таким выводам пришли во втором квартале 2012 года авторы исследования с неутешительным названием The Big Data Gap (с англ. gap – «расхождение», в данном контексте между теоретическими выгодами и реальным положением дел). По результатам опроса 151 ИТ-директора в ближайшие два года объемы хранимых данных в государственных учреждениях увечатся на 1 Петабайт (1024 Терабайт). В то же время извлекать выгоды из постоянно растущих информационных потоков становится все сложнее, сказывается недостаток доступного пространства в СХД, затрудняется доступ к нужным данным, не хватает вычислительной мощности и квалифицированного персонала.
Находящиеся в распоряжении ИТ-менеджеров технологии и приложения демонстрируют существенное отставание от требований реальных задач, решение которых способно принести большим данным дополнительную ценность. 60% представителей гражданских и 42% оборонных ведомств пока только занимаются изучением феномена больших данных и ведут поиск возможных точек его приложения в своей деятельности. Основной, по мнению ИТ-директоров федеральных органов власти, должно стать повышение эффективности работы – так считают 59% респондентов. На втором месте находится повышение скорости и точности принимаемых решений (51%), на третьем – возможность строить прогнозы (30%).
Как бы там ни было, но потоки обрабатываемых данных продолжают расти. На увеличение объемов хранимой информации в течение последних двух лет указали 87% опрошенных ИТ-директоров, на сохранение этой тенденции в перспективе ближайших двух лет рассчитывают уже 96% респондентов (со средним приростом 64%). Чтобы суметь воспользоваться всеми преимуществами, которые сулят большие данные, принимавшим участие в опросе учреждениям понадобится в среднем три года. Пока только 40% органов власти принимают стратегические решения, основываясь на накапливаемых данных, и лишь 28% взаимодействуют с другими организациями для анализа распределенных данных.
- Низкое качество данных.
В большом доме всегда сложнее навести порядок, нежели в крохотной квартирке. Здесь можно провести полную аналогию с большими данными, при работе с которыми очень важно придерживаться формулы `мусор на входе — золото на выходе`. К сожалению, современные инструменты управления мастер-данными недостаточно эффективны и нередко приводят к обратным ситуациям (`золото на входе — мусор на выходе`).
- Метаданные: осведомлен – значит вооружен.
Запрос, который хорошо справляется с поиском сотни строк из миллиона, может не справиться с таблицей из ста миллиардов строк. Если данные часто меняются, крайне важно вести журнал и проводить аудит. Выполнение этих несложных правил позволит располагать важной для выработки методики хранения и работы с данными информации об объеме данных, скорости и частоте его изменения.
- Скажи мне кто твой друг – и я скажу кто ты.
Правильно интерпретировать скрытые в массивах больших данных тенденции и взаимосвязи могут в буквальном смысле считанные подготовленные специалисты. В некоторой степени их способны заменить фильтры и распознаватели структур, но качество получаемых на выходе результатов пока оставляет желать лучшего.
- Визуализация.
Одноименный раздел статьи наглядно иллюстрирует всю сложность и неоднозначность используемых подходов для визуализации больших данных. В то же время, представление результатов в доступной для восприятия форме подчас имеет критически важное значение.
- Время – деньги.
Просмотр данных в реальном времени означает необходимость постоянного пересчета, что далеко не всегда приемлемо. Приходится идти на компромисс и прибегать к ретроспективному способу аналитики, например, на базе кубов, и мириться с отчасти устаревшими результатами.
- Палить из пушки по воробьям.
Никогда нельзя знать заранее на каком временном промежутке большие данные представляют особую ценность и наиболее релевантны. А ведь сбор, хранение, анализ, создание резервных копий требует немалых ресурсов. Остается оттачивать политику хранения и, конечно, не забывать применять ее на практике.
Oracle: Решение проблемы больших данных в модернизации ЦОДов
Результаты исследования корпорации Oracle свидетельствуют о том, что многие компании, по всей видимости, застигнуты врасплох бумом «больших данных».
«Борьба с «большими данными», похоже, станет самой большой ИТ-задачей для компаний в ближайшие два года, – считает Луиджи Фрегуйя (Luigi Freguia), старший вице-президент по аппаратному обеспечению Oracle в регионе EMEA. – К концу этого периода они либо справятся с ней, либо значительно отстанут в бизнесе и будут далеки как от угроз, так и от возможностей «больших данных».
Задача по «освоению» больших данных является уникальной, признают в Oracle. Главным же ответом компаний на вызовы big data должна стать модернизация корпоративных центров обработки данных (ЦОД).
Чтобы оценить степень готовности компаний к изменениям внутри ЦОДов, на протяжении почти двух лет Oracle вместе с аналитической компанией Quocirca собирала данные для исследования Oracle Next Generation Data Centre Index (Oracle NGD Index). Этот индекс оценивает прогресс компаний в вопросе продуманного использования ЦОДов для улучшения производительности ИТ-инфраструктуры и оптимизации бизнес-процессов.
Исследование состояло из двух фаз (циклов), и аналитики заметили существенные изменения всех ключевых показателей уже на пороге второго этапа. Средний балл по Oracle NGD Index, который набрали участники опроса из Европы и Ближнего Востока, составил 5,58. Максимальный балл –10,0 – отражает наиболее продуманную стратегию использования ЦОДов.
Средний балл (5,58) стал выше по сравнению с первым циклом исследования, проведенным в феврале 2011 года, – 5,22. Это говорит о том, что компании в ответ на бум «больших данных» увеличивают инвестиции в стратегии развития ЦОДов. Все страны, отрасли и направления в рамках отраслей, охваченные исследованием, повысили индекс Oracle NGD Index по результатам второго цикла в сравнении с первым.
Скандинавия и регион DCH (Германия/ Швейцария) занимают лидирующие позиции по устойчивому развитию с индексом (Sustainability Index) в 6,57. Далее в этом рейтинге следует Бенилюкс (5,76) и, затем, Великобритания с показателем 5,4, что уже ниже среднего уровня.
У России, которая была включена в список стран/регионов только во втором цикле исследования и не участвовала в первом, есть значительный потенциал для роста (показатель 4,62), отмечают аналитики.
Согласно исследованию, российские организации рассматривают поддержку роста бизнеса в качестве важной причины для инвестиций в ЦОДы. Более 60% компаний видят необходимость таких инвестиций сегодня или в ближайшем будущем, предполагая, что организации в скором времени обнаружат, что конкурировать становится невероятно сложно, если и пока не сделать соответствующие инвестиции.
В целом в мире доля респондентов с собственными корпоративными ЦОДами снизилась с 60% по результатам первого цикла исследования до 44% на втором цикле исследования, напротив, использование внешних ЦОДов возросло на 16 пунктов до 56%.
Лишь 8% респондентов заявили, что им не нужны новые мощности ЦОДа в обозримом будущем. 38% респондентов видят необходимость в новых мощностях ЦОДа в пределах двух ближайших лет. Лишь 6,4% респондентов сообщили, что в их организации нет плана устойчивого развития, связанного с использованием ЦОДа. Доля руководителей ЦОДов, которые просматривают копии счетов на оплату электроэнергии, выросла с 43,2% до 52,2% за весь период исследования.
Инвестиции в Big Data-стартапы
Во второй декаде октября 2012 года сразу три американских стартапа получили инвестирование на развитие приложений и сервисов для работы с Big data. Эти компании на своем примере показывают неугасающий, а возрастающий интерес венчуров к этому сегменту ИТ бизнеса, а также необходимость новой инфраструктуры для работы с данными, пишет TechCrunch 21 октября 2012 года.
Интерес инвесторов к Big data объясняется позитивным прогнозом Gartner о развитии этого сегмента до 2016 года. Согласно исследованию, решения для Big data будут составлять около 232 млрд долларов в структуре ИТ-расходов компаний.
Big data сейчас-это и инфраструктурные предложения и приложения как коробочного, так и облачного типов, это инструмент работы не только больших корпораций, но и среднего, а порой и малого бизнесов.
И это движение рынка вынуждает вендоров иначе смотреть на Big data и менять свой подход в работе с ними, а также меняет взгляд на клиентов-потребителей, которыми теперь являются не только телекоммуникационные или финансовые корпорации.
Индия готовится к буму больших данных
Индийский рынок ИТ постепенно начинает сбавлять темпы развития и индустрии приходится искать новые пути поддержания привычную динамику роста или способы не рухнуть вслед за другими отраслями в периоды мирового экономического кризиса. Разработчики ПО и приложений начинают предлагать новые варианты использования новейших технологий. Так некоторые индийские компании производят анализ покупательской активности на основе больших объемов неструктурированных данных (Big Data) и затем предлагают результаты исследований крупным магазинам и ритейловым сетям. Об этом сообщил 8 октября 2012 года Reuters.
Под пристальное изучение попали камеры видеонаблюдения, отчеты о покупках, запросах в интернете, отчеты о завершенных покупках с помощью того или иного веб-ресурса.
«Эти данные могут нам дать понять о склонности посетителя к той или иной покупке, а следовательно эта информация дает ключ к заключению выгодной сделки для всех сторон», — цитирует Reutes генерального директора Бангалорской компании Mu Sigma Дхирая Раджарама (Dhiraj Rajaram), одной из крупнейших организаций, занимающейся анализом Big Data.
Дхирай Раджарам заметил, что основная часть подобного анализа производится в США, однако сейчас, когда бурное развитие индийского ИТ-рынка начало ослабевать, компании обращают все более пристальное внимание к этому перспективному сегменту.
При этом, индийские компании при работе с Big Data чаще всего используют облачные технологии для хранения и обработки данных и результатов своей деятельности.
Объем общемировых данных, производимых в 2011 году оценивается, по мнению Дхирая Раджарама, в примерно 1,8 зеттабайт — 1,8 миллиарда терабайт, что эквивалентно 200 млрд. полнометражных фильмов высокой четкости.
Помимо анализа запросов и результатов обработки изображения с камер видеонаблюдения, огромный простор для работы Дхирай Раджарам видит в том, сколько информации от пользователей и покупателей появляется в социальных сетях. По его мнению этот относительно новый сегмент ИТ-рынка может стать драйвером всей индустрии в скором времени.
При этом общемировой рост Big Data составит более чем 2 раза с 8,25 млрд долларов сейчас, до 25 млрд долларов в ближайшие несколько лет, считают в Nasscom.
Мода на «Большие данные» расцветает
В 2011 году было принято считать, что современные программные инструменты не в состоянии оперировать большими объемами данных в рамках разумных временных промежутков. Обозначенный диапазон значений носит весьма условный характер и имеет тенденцию к увеличению в большую сторону, поскольку вычислительная техника непрерывно совершенствуется и становится все более доступной. В частности, Gartner в июне 2011 года рассматривает «большие данные» сразу в трех плоскостях – роста объемов, роста скорости обмена данными и увеличения информационного разнообразия[12].
В это время считается, что основной особенностью используемых в рамках концепции больших данных подходов является возможность обработки информационного массива целиком для получения более достоверных результатов анализа. Прежде приходилось полагаться на так называемую репрезентативную выборку или подмножество информации. Закономерно погрешности при таком подходе были заметно выше. Кроме того, такой подход требовал затрат определенного количества ресурсов на подготовку данных для анализа и приведение их к требуемому формату.
Согласно сообщениям СМИ в этот период, «трудно найти отрасль, для которой проблематика больших данных была бы неактуальной». Умение оперировать большими объемами информации, анализировать взаимосвязи между ними и принимать взвешенные решения, с одной стороны, несет потенциал для компаний из различных вертикалей для увеличения показателей доходности и прибыльности, повышения эффективности. С другой стороны, это прекрасная возможность для дополнительного заработка партнерам вендоров – интеграторам и консультантам.
Чтобы подчеркнуть выгоды от развития и внедрения инструментов работы с большими данными компания McKinsey предлагала приведенную ниже статистику. Она имеет привязку преимущественно к рынку США, но ее нетрудно экстраполировать и на другие экономически развитые регионы.
- Потенциальный объем рынка здравоохранения в США составляет $300 млрд в год. Часть этой огромной суммы идет на внедрение современных ИТ, и очевидно, большие данные не останутся в стороне.
- Использование инструментов анализа «больших данных» в розничных сетях потенциально может привести к увеличению прибыльности на 60%.
- Только в США для эффективной обработки «больших данных» понадобится 140-190 тыс. аналитиков и свыше 1,5 млн менеджеров для управления информационными массивами.
- Американские компании в 15 из 17 отраслей экономики располагают большими объемами данных, чем библиотека Конгресса США.
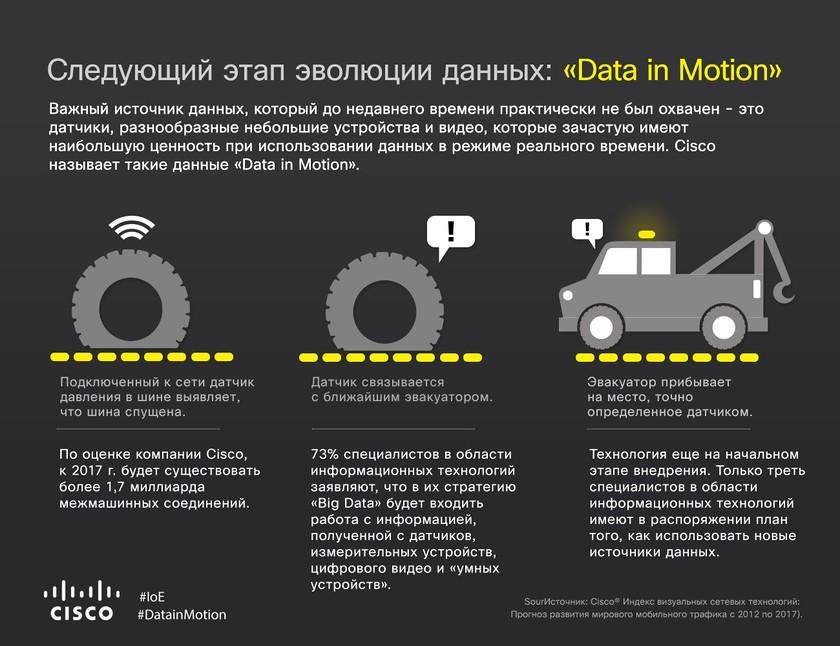
Почему данные стали большими
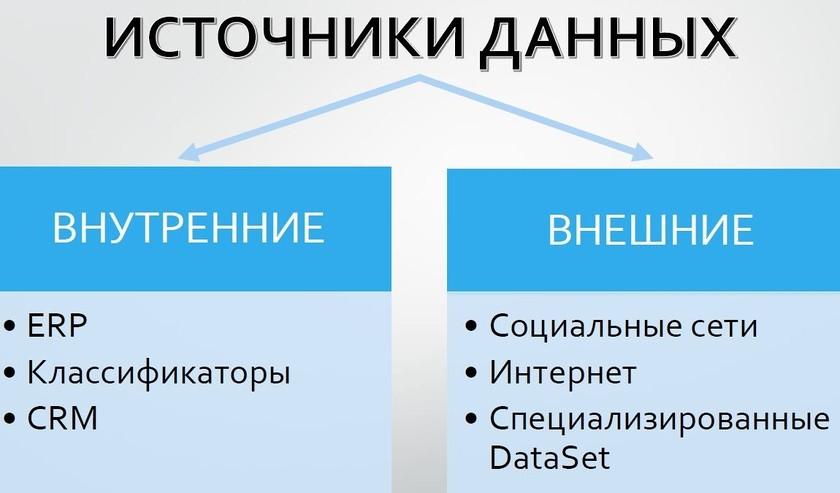
В 2011 году апологеты концепции Big Data заявляют, что источников больших данных в современном мире великое множество. В их качестве могут выступать:
- непрерывно поступающие данные с измерительных устройств,
- события от радиочастотных идентификаторов,
- потоки сообщений из социальных сетей,
- метеорологические данные,
- данные дистанционного зондирования земли,
- потоки данных о местонахождении абонентов сетей сотовой связи,
- устройств аудио- и видеорегистрации.
Собственно, массовое распространение перечисленных выше технологий и принципиально новых моделей использования различно рода устройств и интернет-сервисов послужило отправной точкой для проникновения больших данных едва ли не во все сферы деятельности человека. В первую очередь, научно-исследовательскую деятельность, коммерческий сектор и государственное управление.
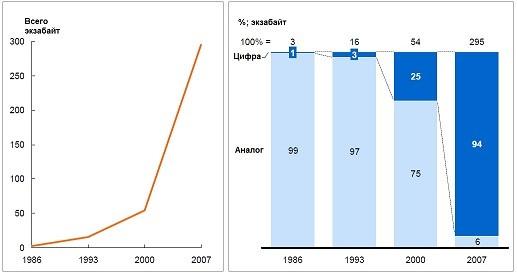
Рост объемов данных (слева) на фоне вытеснения аналоговых средств хранения (справа). Источник: Hilbert and López, «The world’s technological capacity to store, communicate, and compute information», Science, 2011 Global
Несколько показательных фактов этого времени:
- В 2010 году корпорации мира накопили 7 экзабайтов данных, на наших домашних ПК и ноутбуках хранится 6 экзабайтов информации.
- Всю музыку мира можно разместить на диске стоимостью 600 долл.
- В 2010 году в сетях операторов мобильной связи обслуживалось 5 млрд телефонов.
- Каждый месяц в сети Facebook выкладывается в открытый доступ 30 млрд новых источников информации.
- Ежегодно объемы хранимой информации вырастают на 40%, в то время как глобальные затраты на ИТ растут всего на 5%.
- По состоянию на апрель 2011 года в библиотеке Конгресса США хранилось 235 терабайт данных.
- Американские компании в 15 из 17 отраслей экономики располагают большими объемами данных, чем библиотека Конгресса США.
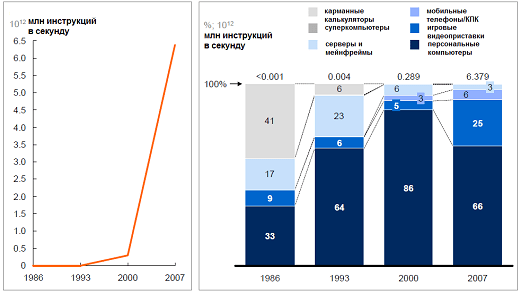
Рост вычислительной мощности компьютерной техники (слева) на фоне трансформации парадигмы работы с данными (справа). Источник: там же.
К примеру, датчики, установленные на авиадвигателе, генерируют около 10 Тб за полчаса. Примерно такие же потоки характерны для буровых установок и нефтеперерабатывающих комплексов. Только один сервис коротких сообщений Twitter, несмотря на ограничение длины сообщения в 140 символов, генерирует поток 8 Тб/сут. Если все подобные данные накапливать для дальнейшей обработки, то их суммарный объем будет измеряться десятками и сотнями петабайт. Дополнительные сложности проистекают из вариативности данных: их состав и структура подвержены постоянным изменениям при запуске новых сервисов, установке усовершенствованных сенсоров или развертывании новых маркетинговых кампаний.
Рекомендации ИТ-директорам
Невиданное прежде разнообразие данных, возникающих в результате огромного числа всевозможных транзакций и взаимодействий, предоставляет собой прекрасную фундаментальную базу для бизнеса по уточнению прогнозов, оценке перспектив развития продуктов и целых направлений, лучшего контроля затрат, оценки эффективности – список легко продолжать сколь угодно долго. С другой стороны, большие данные ставят непростые задачи перед любым ИТ-подразделением, писали эксперты 2020vp.com в 2011 году. Мало того, что они принципиально нового характера, при их решении важно учитывать накладываемые бюджетом ограничения на капитальные и текущие затраты.
ИТ-директор, который намерен извлечь пользу из больших структурированных и неструктурированных данных, должен руководствоваться следующими техническими соображениями[13]:
- Разделяй и властвуй.
Перемещение и интеграция данных необходимы, но оба подхода повышают капитальные и операционные расходы на инструменты извлечения информации, ее преобразования и загрузки (ETL). Поэтому не стоит пренебрегать стандартными реляционными средами, такими как Oracle, и аналитическими хранилищами данных, такими как Teradata.
- Компрессия и дедупликация.
Обе технологии существенно ушли вперед, например, многоуровневая компрессия позволяет сокращать объем «сырых» данных в десятки раз. Впрочем всегда стоит помнить какая часть сжатых данных может потребовать восстановления, и уже отталкиваясь от каждой конкретной ситуации принимать решение об использовании той же компрессии.
- Не все данные одинаковы.
В зависимости от конкретной ситуации диапазон запросов для бизнес-аналитики меняется в широких пределах. Часто для получения необходимой информации достаточно получить ответ на SQL-запрос, но встречаются и глубокие аналитические запросы, требующие применения наделенных бизнес-интеллектом инструментов и обладающих полным спектром возможностей приборной доски и визуализации. Чтобы не допустить резкого увеличения операционных расходов, нужно тщательно подойти к составлению сбалансированного списка необходимых патентованных технологий в сочетании с открытым ПО Apache Hadoop.
- Масштабирование и управляемость.
Организации вынуждены решать проблему разнородности баз данных и аналитических сред, и в этой связи возможность масштабирования по горизонтали и вертикали имеет принципиальное значение. Собственно, как раз легкость горизонтального масштабирования и стала одной из основных причин быстрого распространения Hadoop. Особенно в свете возможности параллельной обработки информации на кластерах из обычных серверов (не требует от сотрудников узкоспециальных навыков) и экономии таким образом инвестиций в ИТ-ресурсы.
Рост спроса на администраторов big data
46% директоров ИТ-служб, опрошенных в конце 2011 года кадровым агентством Robert Half, называют самой востребованной специальностью администрирование баз данных. Администрирование сетей назвали 41% опрошенных, администрирование систем Windows — 36%, техническую поддержку настольных приложений — 33%, а бизнес-аналитику и средства составления отчетов — 28%.
Обработка больших объемов данных становится серьезной проблемой для многих компаний, и это повышает спрос на специалистов по управлению базами данных, заключают в Robert Half. Помимо роста объемов неструктрированных данных (например, сообщений в социальных сетях), спрос повышается из-за подготовки к введению в Европе новых нормативных требований — в том числе стандартов платежеспособности Solvency II для страховых компаний и стандартов капитала и ликвидности Basel III для банковского сектора.
Аналитики Robert Half предсказывают также дефицит специалистов по мобильным и облачным технологиям. Их вывод основан на том, что 38% опрошенных ИТ-директоров главным направлением инвестиций назвали мобильные технологии, а 35% — виртуализацию.
Появление термина «Большие данные»
Непосредственно термин «большие данные» появился в употреблении только в конце 2000-х. Он относится к числу немногих названий, имеющих вполне достоверную дату своего рождения — 3 сентября 2008 года, когда вышел специальный номер старейшего британского научного журнала Nature, посвященный поиску ответа на вопрос «Как могут повлиять на будущее науки технологии, открывающие возможности работы с большими объемами данных?». Специальный номер подытоживал предшествующие дискуссии о роли данных в науке вообще и в электронной науке (e-science) в частности[14].
Можно выявить несколько причин, вызвавших новую волну интереса к большим данным. Объемы информации росли по экспоненциальному закону и ее львиная доля относится к неструктурированным данным. Другими словами, вопросы корректной интерпретации информационных потоков становились все более актуальными и одновременно сложными. Реакция со стороны ИТ-рынка последовала незамедлительно – крупные игроки приобрели наиболее успешные узкоспециализированные компании и начали развивать инструменты для работы с большими данными, количество соответствующих стартапов и вовсе превосходило все мыслимые ожидания.
Наряду с ростом вычислительной мощности и развитием технологий хранения возможности анализа больших данных постепенно становятся доступными малому и среднему бизнесу и перестают быть исключительно прерогативой крупных компаний и научно-исследовательских центров. В немалой степени этому способствует развитие облачной модели вычислений.
В это время ожидается, что с дальнейшим проникновением ИТ в бизнес-среду и повседневную жизнь подлежащие обработке информационные потоки продолжат непрерывно расти. И если в конце 2000-х большие данные – это петабайты, ожидалось, что в будущем придется оперировать с экзабайтами и т.д. Прогнозировалось, что в обозримой перспективе инструменты для работы с такими гигантскими массивами информации все еще будут оставаться чрезмерно сложными и дорогими.
1970-е: Эпоха мейнфреймов — появление концепции больших данных
Сама по себе концепция «больших данных» возникла ещё во времена мэйнфреймов и связанных с ними научных компьютерных вычислений[15]. Как известно, наукоемкие вычисление всегда отличались сложностью и обычно неразрывно связаны с необходимостью обработки больших объемов информации.
Ссылки
- Как анализировать большие данные
- Большие планы на «большие данные»
- Double-Digit Growth Forecast for the Worldwide Big Data and Business Analytics Market Through 2020 Led by Banking and Manufacturing Investments, According to IDC
- Интернет вещей затмил большие данные
- США: Белый дом опубликовал отчет о больших данных и дифференциальном ценообразовании
- Ten Key Take-Aways From the White House Big Data Report
- FTC Public Workshop On Big-Data Discrimination: Assessing the Current Environment
- 92% руководителей довольны проектами больших данных
- Gartner Survey Finds 42 Percent of IT Leaders Have Invested in Big Data or Plan to Do So
- Gartner Says Big Data Creates Big Jobs: 4.4 Million IT Jobs Globally to Support Big Data By 2015
- Managing Big Data: Six Operational Challenges
- Gartner Says Solving ‘Big Data’ Challenge Involves More Than Just Managing Volumes of Data
- Making the Most of Big Data
- Большие Данные — новая теория и практика
- 2012-й: «облачный» год для «больших данных»





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Оставить комментарий