
Как с помощью анализа цифрового портрета и алгоритмов машинного обучения можно точно предсказывать возможность увольнения сотрудника в ближайшем будущем?
Марина Рябова, аналитик, РТК-Солар, Москва, e-xecutive.ru
Предсказание увольнений: шаманство или наука?
Представьте, что вам говорят: поведение человека, который принял решение уволиться или близок к нему, можно предсказать. В голове тут же начинают крутиться шестеренки: да это же круто – экономия на найме и обучении замещающих работников, целые нервы HR-менеджера, руководителей и стабильная непрерывная работа команды! Следующая мысль: это невозможно, слишком много факторов, которые сложно учесть. Нет, не пойдет. Давайте попробуем понять, за счет чего такой прогноз стал реальностью, по крайней мере, для тех сотрудников, которые работают на ПК.
Офисный работник участвует в онлайн-встречах, отвечает на письма, использует определенные приложения. День за днем выполняя свои обязанности, он формирует свой цифровой портрет. Что же происходит, когда человек решает сменить работу, и как можно спрогнозировать распространенную причину увольнений – эмоциональное выгорание? Никакой магии в этом нет, а математическая статистика и data science.
Когда увольнение можно спрогнозировать?
Первый пример. В компанию пришла молодая девушка-технолог. Хорошее резюме, небольшой, но релевантный опыт работы. Проработав несколько месяцев, она со скандалом была уволена. Причиной стало то, что она начала рассылать письма коллегам с предложением организовать свой стартап, используя ноу-хау отдела и клиентскую базу компании. Коллеги рассказали все директору. А если бы ей удалось их убедить? Прощай, бизнес! Новички – это повышенный риск для организации, но они зачастую не могут причинить большой ущерб.
Аномальную активность в почте можно отследить по нескольким критериям: меняется количество писем в почте сотрудника, появляются определенные маркеры – «стоп-слова». «Диверсантку» можно было вычислить только по изменению характера переписки.

Второй пример. Технический директор достаточно крупной производственной компании решил сменить сферу деятельности. Причиной называл отсутствие перспектив развития, «зарубание» инициатив руководством. Человек записался на популярные IT-курсы, полгода отучился и начал ходить на собеседования. Еще пара месяцев и он уволился, найдя «работу своей мечты». Для руководства это была существенная потеря – внезапный уход квалифицированного специалиста. Но таким ли внезапным он был?
За полгода до того, как он положил заявление на стол, в его рабочем графике появились изменения. Например, стали наблюдаться длительные перерывы, их можно отследить по активности на рабочем компьютере, в это время он проходил задания на курсе. Снизилась его продуктивность – ведь он больше не был замотивирован на долгосрочный результат. За несколько месяцев эта картина стала еще более явной – он начал брать дни за свой счет и в счет отпуска, чтобы ходить на собеседования. На графике представлены реальные данные – динамика рабочего времени и перерывов в работе уволившегося специалиста.
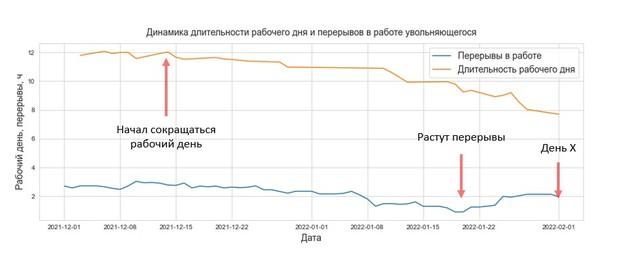
Имеет ли смысл прогнозировать увольнения?
Есть мнение, что прогнозировать увольнения работников – неблагодарное дело. Интерпретация результатов анализа цифрового профиля в ряде случаев может быть неверной, а действия человека не ограничиваются действиями на его рабочем компьютере. Да и поводом для увольнения может стать внешняя причина – например, хорошая работа хедхантера конкурента. С одной стороны, это так. Но с другой, бывают ситуации, когда анализ данных с рабочих компьютеров сотрудников позволяет определить, например, выгорание ключевых специалистов. На российском рынке есть разработки, в которых используются алгоритмы, позволяющие выявлять признаки профессионального выгорания у сотрудников.
Ниже я приведу еще примеры, в каких случаях увольнения реально предсказать, и постараюсь на пальцах объяснить механизм такого прогноза.
1. Эмоциональное выгорание
Увольняется юрист. Вздыхая, говорит о прекрасном коллективе и удобном рабочем месте. Но на другой чаше весов оказались пудовые 14 документов на параллельном согласовании и 2 суток на полный цикл согласования. Постоянные переработки, напряженный темп работы – выгорание за несколько месяцев было обеспечено.
Синдром эмоционального выгорания (или синдром супермена) представляет собой процесс постепенной утраты эмоциональной и физической энергии, проявляющийся в симптомах эмоционального, умственного истощения, физического утомления, личностной отстраненности и снижения удовлетворения от исполненной работы.
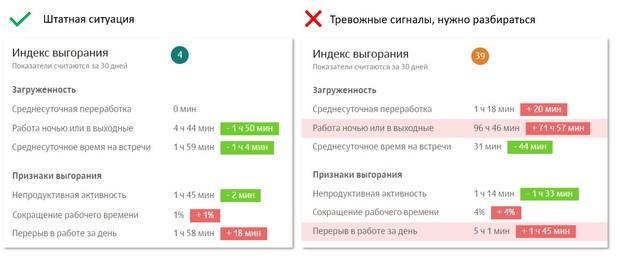
На иллюстрации выше – скриншоты одной из систем мониторинга эффективности труда сотрудников. Слева – нормальные показатели динамики цифрового профиля. Справа – показатели, на которые стоит обратить внимание руководителю или HR-менеджеру.
2. Невозможность развития / недостаточный доход
Казалось бы, как можно предугадать увольнение по этой причине, имея в распоряжении только цифровой профиль работника? Однако варианты есть. Например, отслеживание динамики рабочего времени и длительных перерывов в работе. Или оценка продуктивности: непродуктивным считается время, которое работник проводит в непрофильных для его должности приложениях (условный YouTube или соцсети для бухгалтера).
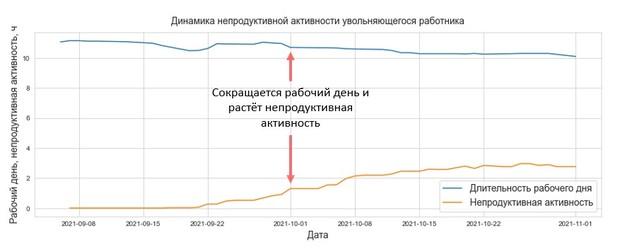
На графике – динамика рабочего времени и непродуктивной активности уволившегося работника. Он ушел через 2 месяца после того, как была зафиксирована тенденция к снижению продуктивности.
3. Лучшее предложение извне
Из компании ушел руководитель проекта, через некоторое время начали увольняться люди из его команды. Подписывая заявление об уходе, они честно рассказывали, что идут работать к своему бывшему руководителю. Это называется «схантили» команду. По изменению характера работы отследить случай, когда человек меняет работу по приглашению извне, очень сложно. Здесь больше имеют значение такие факторы, как должность, стаж работы в компании, пол, возраст, удобство расположения офиса.
Данные, накопленные в нашей компании, говорят о том, что есть статистически значимая связь между стажем работы в компании и вероятностью увольнения. Наиболее рискованный стаж – меньше 3 лет. Если рассматривать его вкупе с остальными факторами, можно получить портрет человека, который может на определенном этапе развития покинуть команду.
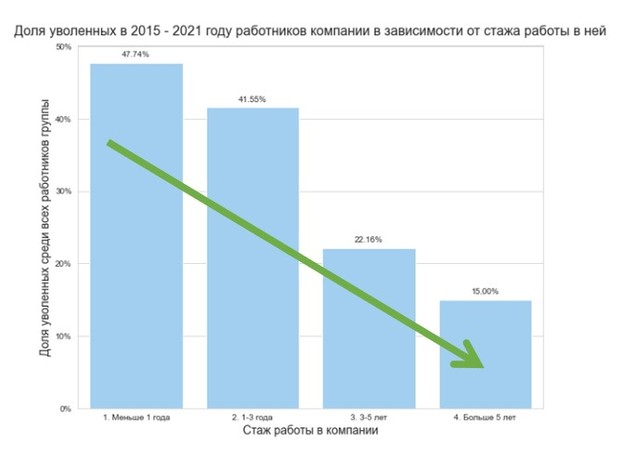
Именно статистика раньше служила основным инструментом при ручном анализе узких мест в работе специалиста по кадрам. Статистика помогает делать то же самое сейчас – но уже не человеку, а искусственному интеллекту. Давайте посмотрим, какие подходы к аналитике увольнений используются ведущими компаниями.
Предсказание увольнений: распространенные подходы
Все методы предиктивной аналитики базируются на больших данных и на машинном обучении. Основные различия кроются в наборах данных, способах их сбора и выборе алгоритма обучения. Вот как это делают крупные компании, заинтересованные в сбережении своих кадров.
2018 год: опыт компании EY
EY (бывшая Ernst & Young) – крупная британская аудиторско-консалтинговая компания. Для прогноза увольнений в компании использовали данные о рабочем времени из СКУД, данные по заработной плате и развитии работника в компании. Модель оказалась рабочей, но при ее построении пришлось решать этический вопрос об использовании личных данных работника, напрямую не относящихся к его рабочим обязанностям. Еще одна сложность, с которой столкнулись исследователи – разрозненность и мозаичность исходных данных. Информация приходит по разным каналам, в разном формате, некоторые данные собираются фрагментарно.
2019 год: опыт компании SAS
SAS – американская компания-разработчик программ для статистического анализа и систем класса Business Intelligence. Используя персональные данные своих работников за несколько лет, они научились с высокой точностью предсказывать увольнение работников ряда должностей. В этом подходе хорошо все, кроме одного: работники должны знать, что их личные данные, включая уровень зарплаты, активность в соцсетях и прочее, используются для анализа. И снова встает вопрос об этичности использования таких данных.
2021 год: опыт компании «Ростелеком»
HR-команда «Ростелекома» рассказала о том, как они сэкономили миллиарды рублей, вовремя предупредив выгорание 70% ключевых сотрудников, попавших в зону риска. Для прогнозирования использовалось несколько методов машинного обучения, статистика по каждому сотруднику и статистика по отрасли от Росстата.
Во всех перечисленных примерах работают похожие алгоритмы. Посмотрим, что у них под капотом.
Работает или увольняется: как это определяет машина
Работу алгоритмов машинного обучения часто считают магией или таинственным черным ящиком, однако в них используются те же подходы, что и в обычной «человеческой» жизни.
Приведу пример. Казалось бы, можно точно спрогнозировать, какую оценку ты получишь на экзамене. Выучил все билеты, получил «отлично», не готовился – «неуд». Но в реальной жизни есть множество факторов, которые могут этот прогноз скорректировать. Скажем, по дороге на экзамен ты неудачно упал, нога так сильно болит, что тебе уже не до учебы, и ты допускаешь нелепую ошибку. Или так сильно волнуешься, что преподаватель ставит четверку только потому, что видит твою неуверенность. И наоборот: вытянул единственный билет, ответ на который знал, и в итоге выплыл на «хорошо» там, где уже смирился с необходимостью пересдачи.
Как предсказать вероятность получения хорошей/плохой оценки на экзамене с помощью алгоритмов машинного обучения? Мы бы загрузили в модель данные по нескольким сотням (или тысячам) студентов, уже прошедших экзамен. Мы знаем, кто из них сдал, кто провалился. Рассматриваем признаки: пол, предыдущие оценки по разным предметам, темперамент, время года, оценку знания предмета… Все эти признаки модель проанализирует и определит наиболее важные, которые дают наибольший вклад в правильный ответ. На этом этапе она обучается.
Следующим шагом проверим, как работает модель: берем данные, которые она еще не видела, и смотрим, как корректно она определяет целевой признак (факт сдачи экзамена). Если метрики качества на тестовой выборке достигают 80-90% и выше, модель считаем рабочей и начинаем применять для предсказания будущих событий.
В случае с предсказанием увольнений работает та же схема. На вход модели подаются разносторонние признаки цифрового профиля, а она выбирает наиболее важные, влияющие на вероятность увольнения. На выходе получаем предсказание: «на данный момент с такой-то вероятностью этот сотрудник может уволиться». Было бы здорово также добавить, когда он уйдет. Например, через 2,5 месяца. Но на время ухода влияет много внешних факторов, в первую очередь – состояние рынка труда. Поэтому такой машинный прогноз будет крайне неточным.
Так выглядит общий принцип машинного обучения. А теперь расскажу, как это делали мы.
Машинное обучение на алгоритмах Yandex
Итак, целевой признак нашей модели – увольняется человек (это 1) или нет (это 0). Целевой признак один, а вот параметров, по которым происходит его определение, может быть много. Мы используем около 50 характеристик цифрового профиля: данные по продуктивности, данные по встречам и по работе с почтой. Из этических соображений не исследуются активность в соцсетях и прочая персональная информация.
Существует несколько видов алгоритмов машинного обучения. Когда исследуется несколько десятков параметров, подходят древовидные алгоритмы, например, для нашего случая идеально подходит Catboost от компании Yandex. Алгоритмы машинного обучения принимают на вход не только числовые признаки, но и категориальные. Например, стаж работы, пол, должность. Catboost работает и с категориями, и с числами «из коробки», без дополнительной обработки.
Так выглядят шаги построения модели. Причем первый шаг – сбор информации – обычно самый трудоемкий, и его автоматизация – отдельная гордость, за которой стоит огромный труд команды.
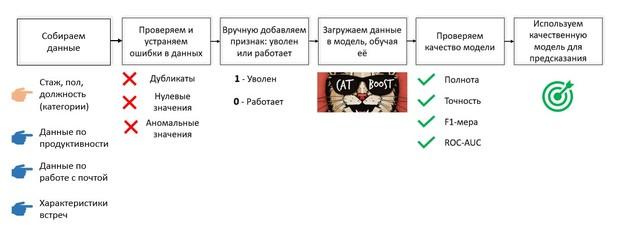
Важные замечания:
- Качество модели напрямую зависит от объема подаваемых ей на вход данных.
- Модель, дающую высокие метрики, на уровне не ниже 80%, можно использовать для прогнозирования увольнений в будущем.
- HR-специалист или руководитель, используя данные прогноза, может предотвратить нежелательное увольнение, предложив работнику варианты развития внутри компании. Иногда достаточно просто уделить время обсуждению его насущных проблем – может оказаться, что они решаются с минимальными затратами.
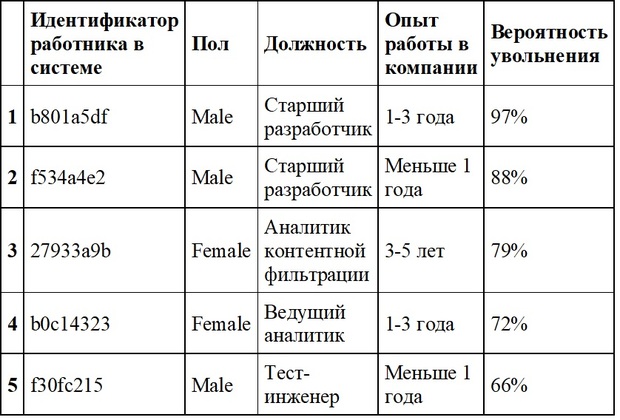
Мы можем предсказать увольнение работника в двух из трех самых распространенных ситуаций. Результат работы модели – вероятность увольнения конкретного работника. Вот полученные с помощью нашей модели данные о вероятности увольнения работников одного из подразделений нашей компании. Они действительно уволились в рассматриваемый период:





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Оставить комментарий